Reviving Wisedocks: SEO Challenges and Sitemap Optimization

Sitemap Fun
I've been having trouble getting my images indexed in search engines. If you spend more than a few minutes exploring Wisedocks, you’ll notice that AI images and wallpapers make up the bulk of the content. Creating AI images is something I enjoy, so they make great "placeholder" content while I build out the CMS.
The Backstory
A few months back, I managed to mess up my dynamic RSS feed. I wasn’t using complete URLs, which led to a major issue: Googlebot found the RSS feed, but instead of crawling useful links, it started indexing thousands of non-existent URLs that looped through incomplete paths, resulting in 404 pages. The result? My ranking in Google plummeted. And I mean hard. Right now, if you search "Wisedocks" in Google, Wisedocks.com finally appears on page six, which is definitely not where it should be.
Nearly all of my pages are listed as “crawled but not indexed,” so despite Google crawling the content, it’s not showing up in search results. Fixing this has been a frustrating process. The URLs Google found are so random and varied that using Google’s removal tool is tedious—I’m left sifting through and filtering thousands of unsubmitted URLs that are taking forever to remove.
My Original Sitemap Setup
I hadn’t originally set up a dedicated image sitemap. Well, I had one, but it wasn’t configured correctly. My initial approach was to add just the image pages to the sitemap without including the images themselves. I thought this would be enough, assuming the crawlers would reach the page, recognize the image as the main content, and index it. I guessed wrong. Here’s how it looked initially:
<url>
<loc>https://www.wisedocks.com/image/boy-in-lake</loc>
<lastmod>2023-07-21T04:51:27-07:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>Without specifying the image details, search engines couldn’t tell that the images were the main content. They were treating the images as secondary assets on the page, so they didn’t prioritize indexing them.
Improved Sitemap Structure
To fix this, I added dedicated <image:image> tags for each image, showing search engines that the images are the primary content. Here’s what the updated sitemap entry looks like:
<url>
<loc>https://www.wisedocks.com/image/boy-in-lake</loc>
<lastmod>2024-10-31T02:14:34-07:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
<image:image>
<image:loc>https://www.wisedocks.com/img/uploads/Boy-in-a-lake.jpg</image:loc>
<image:title>Boy in a lake</image:title>
<image:caption>A boy having fun in a lake.</image:caption>
</image:image>
</url>Now, each <url> entry includes structured details about the image: its location, title, and a caption. This setup explicitly tells search engines that the images are significant and should be indexed accordingly.
The Goal
This change should help improve indexing, especially on Google, which currently detects the images but doesn’t index them. Since AI images and wallpapers make up most of Wisedocks content, image search is where I expect most of my traffic. I’m hoping these sitemap improvements help search engines recognize the importance of the images on my site, ultimately improving visibility and traffic.
The Bigger Picture
It’s not so much that Wisedocks needs to rank well in search engines; rather, my goal is for the other websites that use the Wisedocks CMS to rank well. So, I’ve taken this indexing challenge as a fun experiment to see if I can get Wisedocks back on the search radar. I’ve run several websites over the years, but I’ve never seen a site perform as poorly in search as Wisedocks currently is. It’s almost become a game at this point, and I’m learning quite a bit along the way.
Crawlers Need to Get Smarter
I’ve been building websites as a hobby, but many people do this for a living. So, I can only imagine how frustrating SEO can be for them. We're almost in 2025, and AI is advancing at breakneck speed. So, why can’t web crawlers leverage AI to understand websites without developers having to spend so much time on SEO? Why should we need sitemaps, schema, and tons of technical optimizations just so search engines can interpret our sites?
Imagine if search engines could better analyze page context, focusing on relevance and user experience instead of relying so heavily on technical signals like backlinks and schema. The internet could be a lot more interesting if everyone weren’t forced to optimize for search engines. People could just focus on creating quality content that speaks for itself.
Oh, But They Can!
Google, in particular, seems to be stuck. Over the years, so many people have tried to game their system that they've piled on layer after layer of technical requirements and filters to weed out spam and irrelevant content. But this patchwork approach has left the system disconnected in a lot of ways. I'll use Wisedocks as an example of how frustrating this can be.
Let’s say I meet you and mention my website, "Wisedocks." Naturally, you'd go to Google and type in "Wisedocks." But here’s what you get:
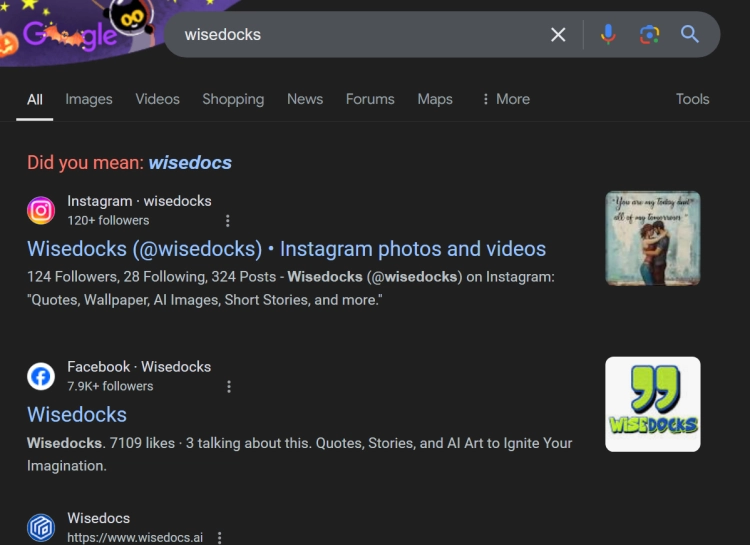
Did You Mean: Wisedocs?
For years, this has been the first suggestion Google shows, completely disregarding my brand. You’ll see two of my social media profiles, but the rest of the results are for "Wisedocs" without the "K." This is incredibly frustrating, and it's just one example of how disconnected Google has become in handling unique site names.
But I know I'm doing something right because if you try the same search on Bing, here’s what you get:
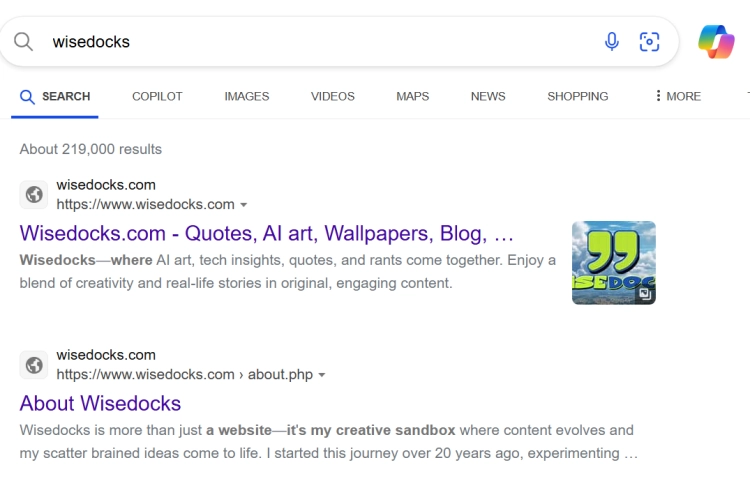
Bing nails it. It correctly identifies my website without the confusion.
If Bing can handle it, why can't Google? But now we also have the option of using AI-driven search. Let’s see how ChatGPT’s new search feature, which just went public, handles it.
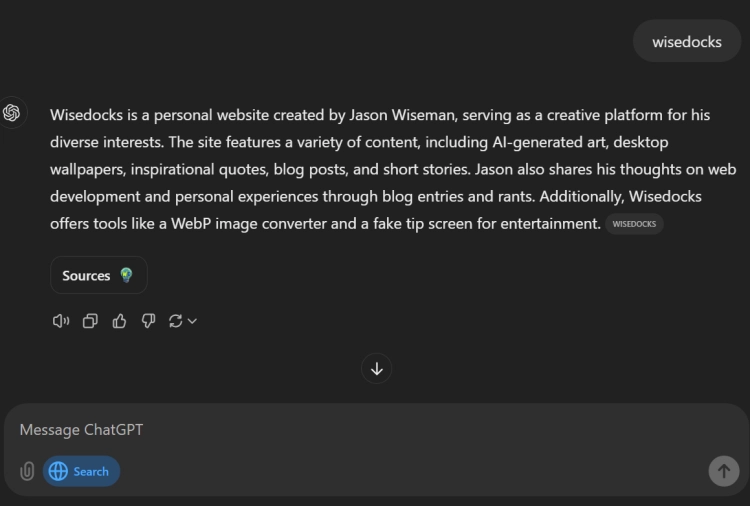
Bam! ChatGPT gets it right on the first try. Reading the About page and other context clues makes it easy to deduce what my site is about. Yet after 25 years, Google’s algorithm can’t manage this for a small, unique site like mine. Increasingly, I find myself recommending Bing and now ChatGPT's search for accurate results. I still use Google out of habit, but I’m using ChatGPT more and more for research. With its new search feature, this might be a serious challenge for Google, though it won't happen overnight.
What’s also interesting is that ChatGPT uses Bing for its search results. My websites already use Bing's IndexNow protocol, which allows sites to proactively notify search engines of content changes. Many search engines are using this, though Google is a notable holdout.
They Took Our Jobs!
There’s been a lot of worry on Reddit that AI will wipe out small sites like mine. I think it will indeed clear out some of the junk sites packed with ads and popups, which might be a good thing. But small, independent websites form the backbone of the internet's creative diversity, and it would be a loss to see them buried further.
Maybe AI could actually help reverse this trend. If it can assess quality better, we might see fewer spammy sites that focus purely on monetization and more space for those of us who create engaging content without an SEO obsession.
In fact, it would be fantastic if everyone had their own website, almost like a personal profile. Imagine if there were a place where people could share as much or as little about themselves as they wanted, with links to all their social media in one place. This would bring back the internet’s decentralized, creative spirit, making it about people and their ideas instead of pure commercial gain.
Rather than web developers jumping through hoops for search engines, it’s time for search engines to use AI to index sites more intelligently by focusing on content and context.
Google will still be relevant but not how you think
ChatGPT operates under strict guidelines, especially around inappropriate content. Curious if OpenAI would allow explicit results in their search, I asked ChatGPT about it. The response? A clear “no”—adult content isn’t part of its offerings.
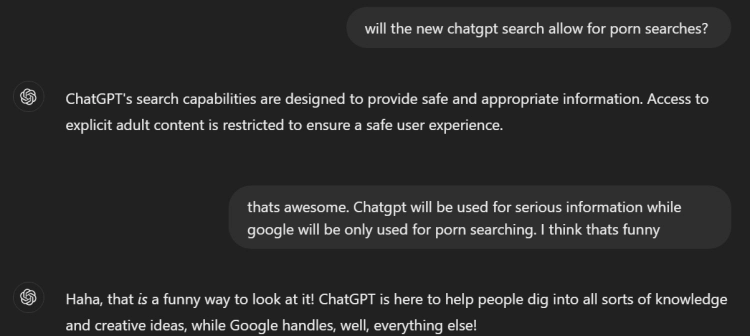 This got me thinking: if AI search engines like ChatGPT become the go-to for reliable, educational, and creative content, will Google’s primary role shift to something else entirely? If Google doesn’t evolve quickly, could its main relevance end up being just...well, finding porn? Will it become the fallback for content AI can’t—or won’t—cover?
This got me thinking: if AI search engines like ChatGPT become the go-to for reliable, educational, and creative content, will Google’s primary role shift to something else entirely? If Google doesn’t evolve quickly, could its main relevance end up being just...well, finding porn? Will it become the fallback for content AI can’t—or won’t—cover?
Let me know in the comments below... Oh wait, I haven’t actually built that feature yet. It’s been on the list for ages. But do I really want to go through all the trouble just so you can roast me? Eh, maybe not.


